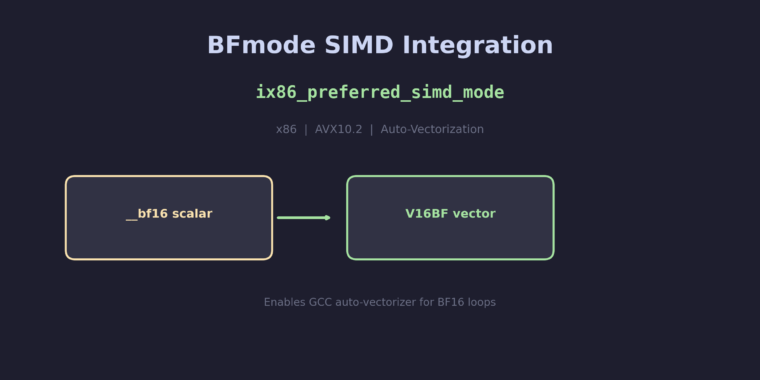
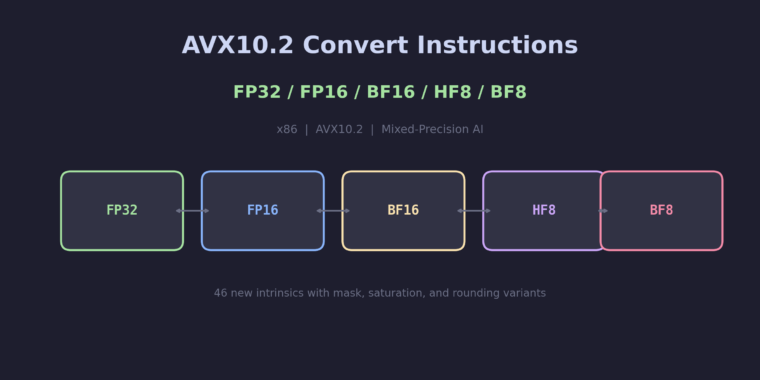
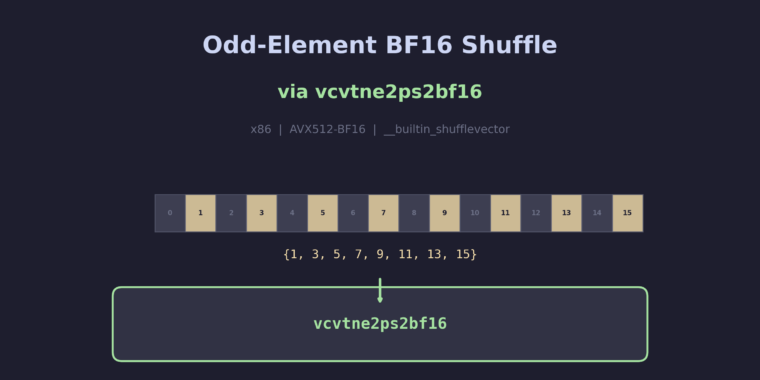
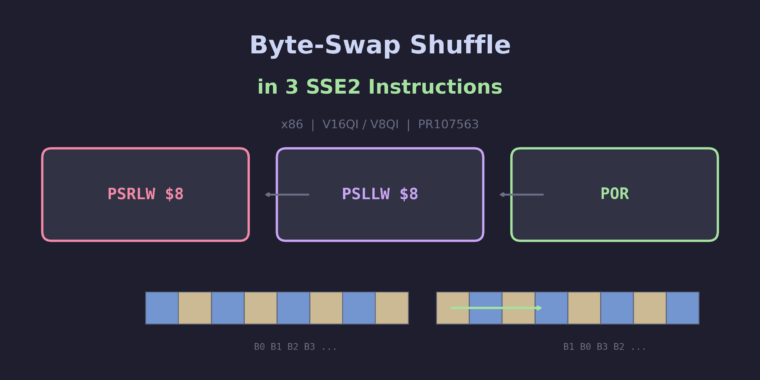
This patch has been committed to the master branch: dd859e93a16 – Support Intel AMX-FP8 This patch adds GCC support for Intel AMX-FP8, a new extension to the Advanced Matrix Extensions (AMX) that performs tile-based matrix multiplication with 8-bit floating-point (FP8) operands and FP32 accumulation. AMX-FP8 doubles the compute density compared to AMX-BF16 by packing twice… Read more Support Intel AMX-FP8 – 8-bit float tile matrix multiply