Python3 implementation of :
- Randomized Algorithm (Chapter 6.4.1)
- Savasere, Omiecinski, and Navathe (SON) Algorithm (Chapter 6.4.3)
Originally described in Book Mining of Massive Datasets. Book is available online:
http://infolab.stanford.edu/~ullman/mmds/ch6.pdf
Datasets Used ( T10I4D100K, T40I10D100K ):
Arguments:
- -f –file Filename
- -s –min_support (default 0.5) Minimal support rate.
- -c –min_confidence (default 0.5) Minimal confidence level.
- -t –process (default 4) How many processes (Set to you core number) (SON algorithm only)
- -p –probability (default 0.1) (Randomized Algorithm only)
3rd Party library needed:
pip3 install efficient-apriori
Sample Run:
python3 random.py -f T40I10D100K.dat -p 0.1 -s 0.05 -c 0.05 python3 son.py -f T40I10D100K.dat -t 10 -s 0.05 -c 0.05
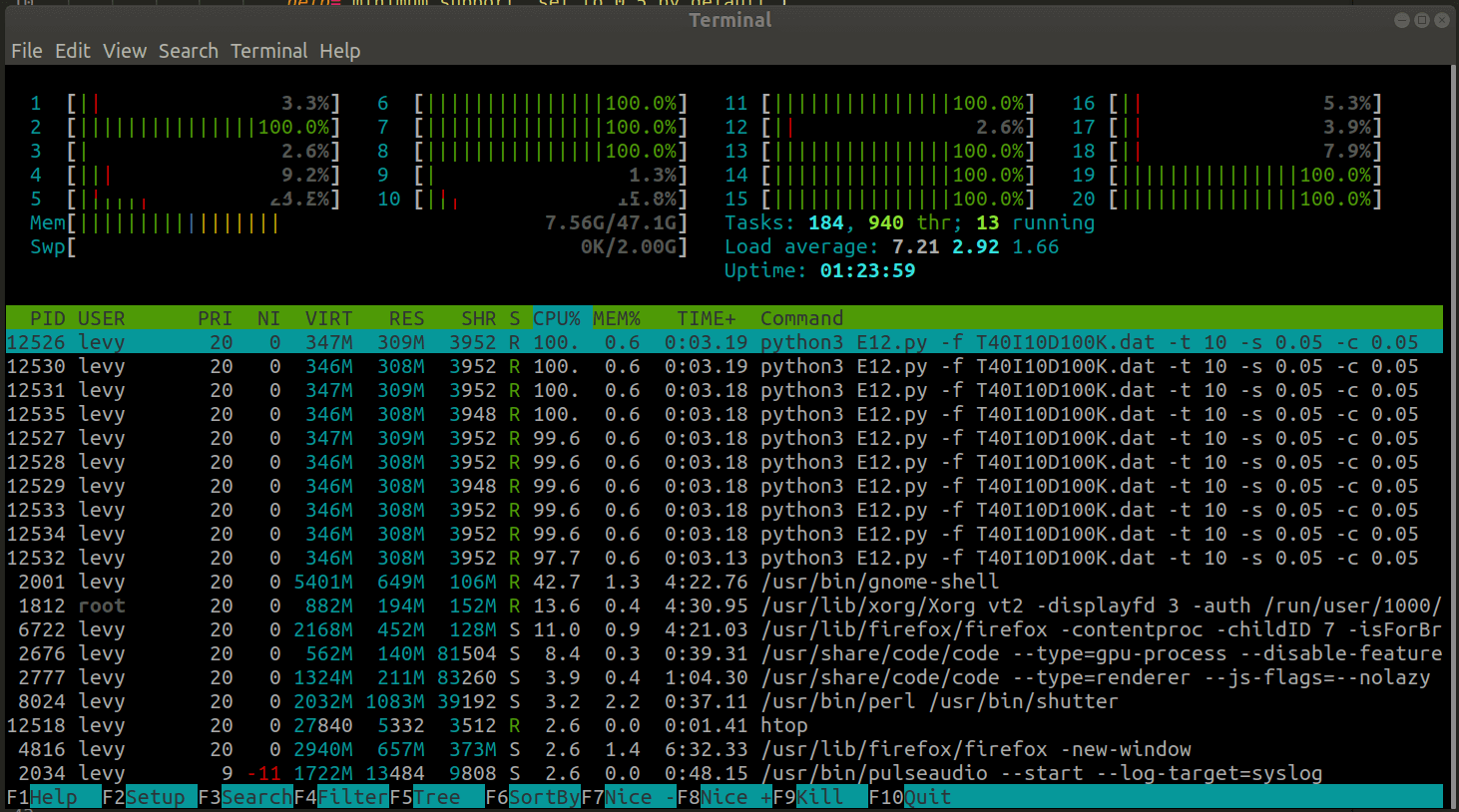
Proof of efficiency:


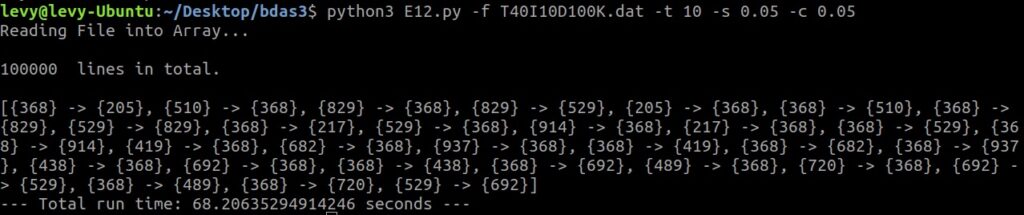
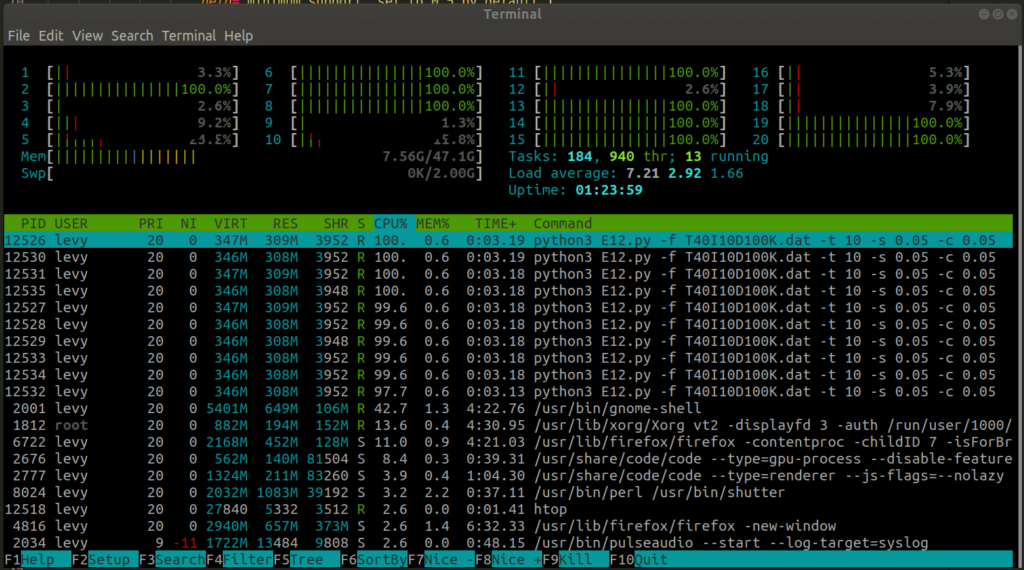
Note: Hyper-threading won’t save your time
Following codes works on Unix-like OS only (Linux Distribution & Mac) due to different mechanism on creating a subprocess. You’ll have to modify the global variable memory_data if on Windows:
“On Linux, multiprocessing forks a new copy of the process to run a pool worker. The process has a copy-on-write view of the parent memory space. As long as you allocate globalDict before creating the pool, it’s already there. Notice that any changes to that dict stay in the child.
On Windows, a new instance of python is created and the needed state is pickled/unpickled in the child. You can use an initializing function when you create the pool and copy there. That’s one copy per child process which is better than once per item mapped.“
I am in windows please help