This patch has been committed to the master branch:
b851bce473d – i386: Integrate BFmode for Enhanced Vectorization in ix86_preferred_simd_mode
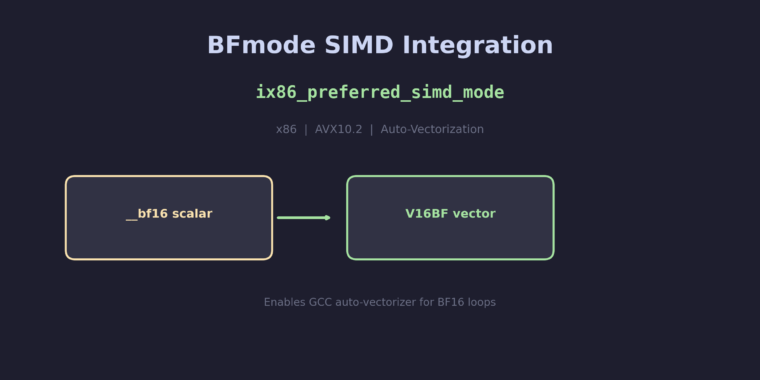
This small but important patch tells GCC’s auto-vectorizer how to choose the best SIMD register width for BF16 operations, enabling automatic vectorization of BF16 loops without manual intrinsics. It’s the final piece that connects all the BF16 arithmetic, comparison, and bitwise patches into a complete auto-vectorization story.
The Problem
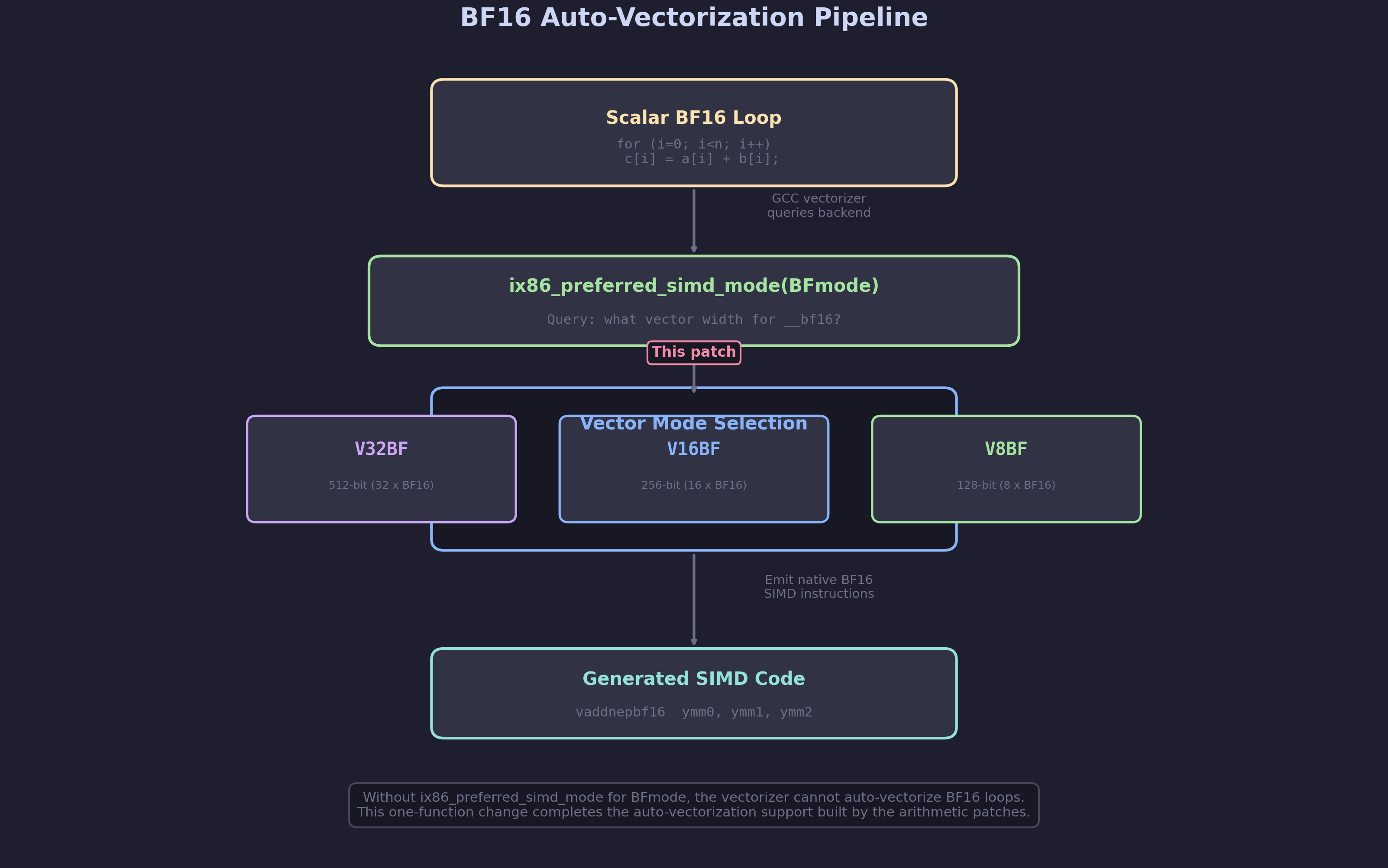
GCC’s tree-level vectorizer works in two phases: first it analyzes a scalar loop to determine if vectorization is profitable, then it queries the target backend to select the appropriate vector width. The query goes through targetm.vectorize.preferred_simd_mode(), which maps scalar modes to their optimal vector mode.
Without a mapping for BFmode, the vectorizer couldn’t auto-vectorize BF16 loops – even though the arithmetic and comparison instructions were all wired up. It had no way to know that __bf16 scalars should map to V8BF, V16BF, or V32BF vectors.
The Fix
A new BFmode case is added to ix86_preferred_simd_mode in i386.cc, mirroring the existing HFmode logic:
case E_BFmode:
if (TARGET_AVX10_2_512)
return V32BFmode; /* 512-bit: 32 x BF16 */
else if (TARGET_AVX10_2_256)
return V16BFmode; /* 256-bit: 16 x BF16 */
else
return word_mode; /* No native BF16 arithmetic */
The logic is straightforward: prefer the widest available SIMD mode when AVX10.2 is available. The cascade checks 512-bit first (requires TARGET_AVX10_2_512), then falls back to 256-bit (requires TARGET_AVX10_2_256), and finally returns word_mode if no native BF16 arithmetic support is available. Returning word_mode signals to the vectorizer that it should not attempt to vectorize BF16 operations on this target.
Why Not 128-bit?
You might notice the function doesn’t return V8BF (128-bit) as a fallback. This is by design: preferred_simd_mode returns the widest mode the target should use. The vectorizer can still choose narrower widths through its costing model, or via related_mode queries. Returning V16BF (256-bit) when only AVX10.2-256 is available allows the vectorizer to also consider V8BF if the loop trip count doesn’t justify 256-bit operations.
The Complete Auto-Vectorization Story
This patch is the capstone of the BF16 vectorization series. With all patches applied, GCC can now take a simple scalar loop like:
void add_bf16(__bf16 *c, const __bf16 *a, const __bf16 *b, int n) {
for (int i = 0; i < n; i++)
c[i] = a[i] + b[i];
}
And automatically produce:
.loop:
vmovdqu ymm0, [rsi + rax] ; load 16 BF16 values from a
vaddnepbf16 ymm0, ymm0, [rdx + rax] ; add 16 BF16 values from b
vmovdqu [rdi + rax], ymm0 ; store 16 BF16 results to c
add rax, 32
cmp rax, rcx
jne .loop
The vectorizer pipeline for this transformation involves:
- preferred_simd_mode (this patch) - tells the vectorizer to use V16BF (256-bit)
- Arithmetic optabs - maps
BF16 +tovaddnepbf16(BF16 arithmetic patches) - Comparison optabs - enables loop exit conditions on BF16 (comparison patches)
- Bitwise optabs - enables reductions with abs/neg (bitwise patches)