
These patches have been committed to the master branch:
f77435aa391 – i386: Support vec_cmp for V8BF/V16BF/V32BF in AVX10.2
89d50c45048 – i386: Enable V2BF/V4BF vec_cmp with AVX10.2 vcmppbf16
61622cfa463 – i386: Utilize VCOMSBF16 for BF16 Comparisons with AVX10.2
These three patches enable native BF16 comparison support in GCC’s x86 backend using AVX10.2 instructions. Together they cover vector comparisons for all BF16 widths (V2BF through V32BF) and scalar comparisons for branch conditions.
Overview
Before AVX10.2, comparing BF16 values on x86 required either converting to FP32 first (using vcvtbf162ps + vcmpps) or doing an integer comparison on the raw bits (which only works for equality and doesn’t handle NaN or signed zero correctly). AVX10.2 introduces two dedicated BF16 comparison instructions:
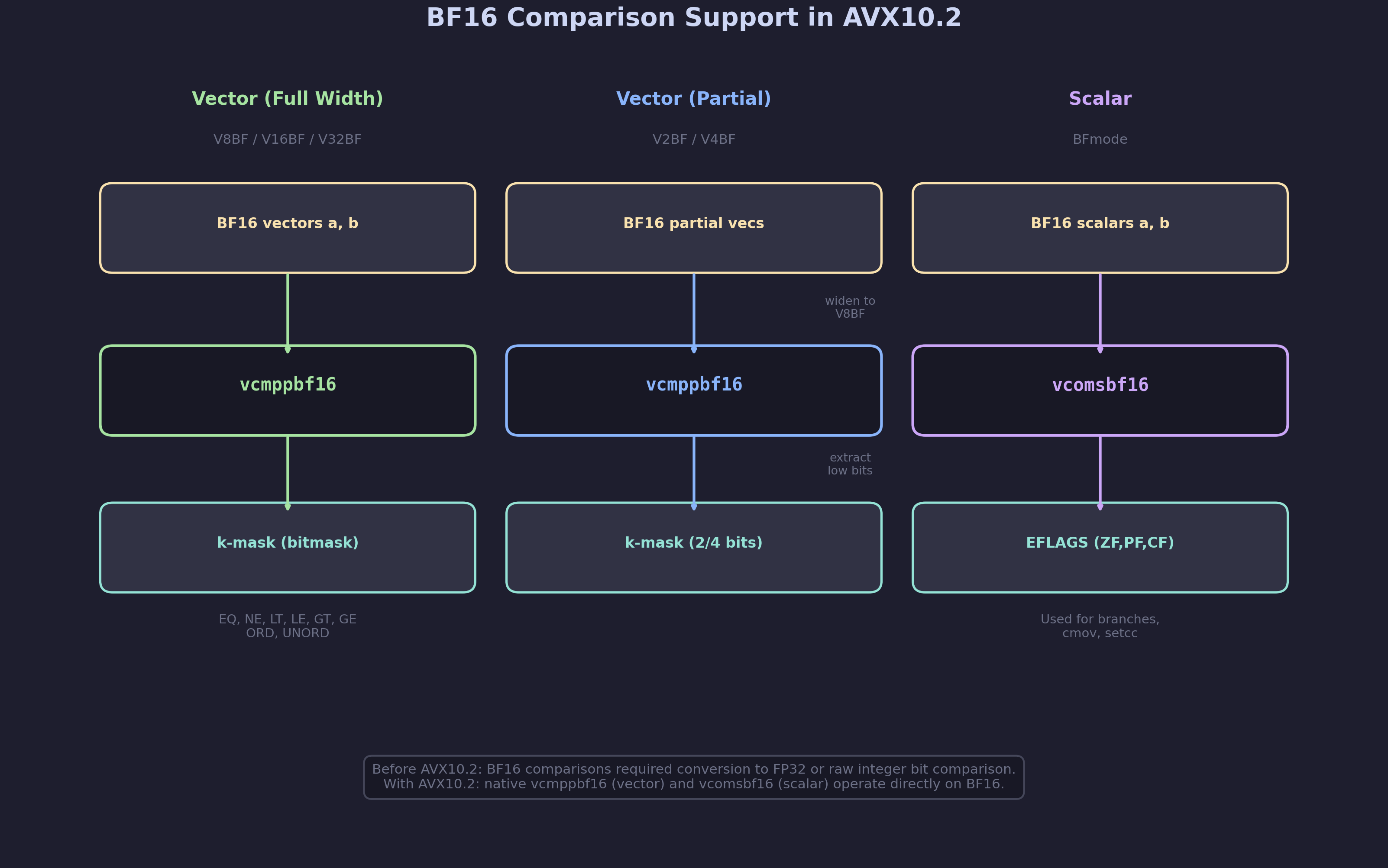
Vector Comparisons – Full Width
AVX10.2 provides vcmppbf16 for packed BF16 comparisons, producing a k-mask bitmask result (like other AVX-512 comparisons). The first commit adds vec_cmp expanders for V8BF, V16BF, and V32BF in sse.md:
(define_expand "vec_cmp<mode><avx512fmaskmodelower>"
[(set (match_operand:<avx512fmaskmode> 0 "register_operand")
(match_operator:<avx512fmaskmode> 1 ""
[(match_operand:VBF_AVX10_2 2 "register_operand")
(match_operand:VBF_AVX10_2 3 "nonimmediate_operand")]))]
"TARGET_AVX10_2_256"
{
bool ok = ix86_expand_mask_vec_cmp (operands[0], GET_CODE (operands[1]),
operands[2], operands[3]);
gcc_assert (ok);
DONE;
})
BF16 comparisons use integer mask results (like AVX-512 masking) rather than vector results. The ix86_use_mask_cmp_p function in i386-expand.cc was updated to return true for BFmode, ensuring the vectorizer selects the mask-based comparison path rather than trying to produce a vector of all-ones/all-zeros results.
The comparison predicate (EQ, LT, LE, UNORD, etc.) is encoded as an immediate operand to vcmppbf16, following the same encoding scheme as vcmpps/vcmppd. The ix86_expand_mask_vec_cmp function maps GCC’s comparison codes (EQ, NE, LT, LE, GT, GE, ORDERED, UNORDERED) to the appropriate x86 comparison predicate immediates.
Vector Comparisons – Partial Width
The second commit extends vec_cmp to V2BF and V4BF in mmx.md. These partial-width comparisons widen to V8BF, perform the comparison with vcmppbf16, then extract the relevant mask bits:
(define_expand "vec_cmp<mode>qi"
[(set (match_operand:QI 0 "register_operand")
(match_operator:QI 1 ""
[(match_operand:VBF_32_64 2 "nonimmediate_operand")
(match_operand:VBF_32_64 3 "nonimmediate_operand")]))]
"TARGET_AVX10_2_256"
{
/* Widen to V8BF, compare, extract low mask bits */
...
})
The mask mode infrastructure (ix86_get_mask_mode) was updated to handle BFmode when AVX10.2 is available, returning QI mode for the 2-element and 4-element cases.
Scalar Comparisons – VCOMSBF16
The third commit enables scalar BF16 comparisons for branch conditions and conditional moves using the vcomsbf16 instruction. This is the BF16 equivalent of vcomiss/vcomisd – it compares two scalar BF16 values and sets the CPU flags (ZF, PF, CF) accordingly.
Key changes in i386-expand.cc:
ix86_expand_branch– adds BFmode handling, assertingTARGET_AVX10_2_256 && !flag_trapping_mathix86_prepare_fp_compare_args– previously BFmode fell through to integer comparison (comparing raw bits via HImode). Now with AVX10.2, it goes through the SSE comparison pathix86_expand_fp_compare– BFmode is restricted tovcomsbf16only (novcomubf16orvcomxbf16variants exist), so the UNSPEC_OPTCOMX and UNSPEC_NOTRAP wrappers are skipped for BFmode
/* ix86_expand_branch - BFmode case */
case E_BFmode:
gcc_assert (TARGET_AVX10_2_256 && !flag_trapping_math);
goto simple;
/* ix86_expand_fp_compare - skip unordered/optcomx for BFmode */
/* We only have vcomsbf16, no vcomubf16 nor vcomxbf16 */
if (GET_MODE (op0) != E_BFmode)
{
if (TARGET_AVX10_2_256 && (code == EQ || code == NE))
tmp = gen_rtx_UNSPEC (CCFPmode, gen_rtvec (1, tmp), UNSPEC_OPTCOMX);
if (unordered_compare)
tmp = gen_rtx_UNSPEC (CCFPmode, gen_rtvec (1, tmp), UNSPEC_NOTRAP);
}
The cost model functions (ix86_multiplication_cost, ix86_division_cost, ix86_rtx_costs) were also updated from SSE_FLOAT_MODE_SSEMATH_OR_HF_P to SSE_FLOAT_MODE_SSEMATH_OR_HFBF_P to include BF16 in SSE cost calculations, ensuring the optimizer makes correct cost-based decisions for BF16 operations.
The -ftrapping-math Restriction
Note the !flag_trapping_math assertion in the scalar path. The vcomsbf16 instruction does not support the “quiet” comparison semantics that GCC needs when -ftrapping-math is enabled (which is the default). With -fno-trapping-math (or -ffast-math), the compiler can freely use vcomsbf16. Without it, scalar BF16 comparisons still fall back to FP32 conversion.
Test Cases
Tests verify vcmppbf16 emission for vector comparisons across all widths, and vcomsbf16 for scalar branch comparisons. The scalar tests use -fno-trapping-math to enable the vcomsbf16 path.
Co-authored-by: Hongtao Liu ([email protected])