
This patch has been committed to the master branch:
8718727509b – x86: Implement Fast-Math Float Truncation to BF16 via PSRLD Instruction
This patch optimizes float to __bf16 conversion under -ffast-math by using a simple bit shift (psrld $16) instead of a dedicated conversion instruction, removing the requirement for AVX512-BF16 or AVX-NE-CONVERT hardware. This makes BF16 conversion available on every x86-64 processor with just baseline SSE2.
The Insight: BF16 = FP32 >> 16
BF16 (bfloat16) is designed so that its bit representation is the upper 16 bits of an IEEE 754 float32. A float-to-BF16 conversion is, at its core, just discarding the lower 16 mantissa bits. This can be achieved with a single right shift by 16 on the 32-bit integer representation of the float.
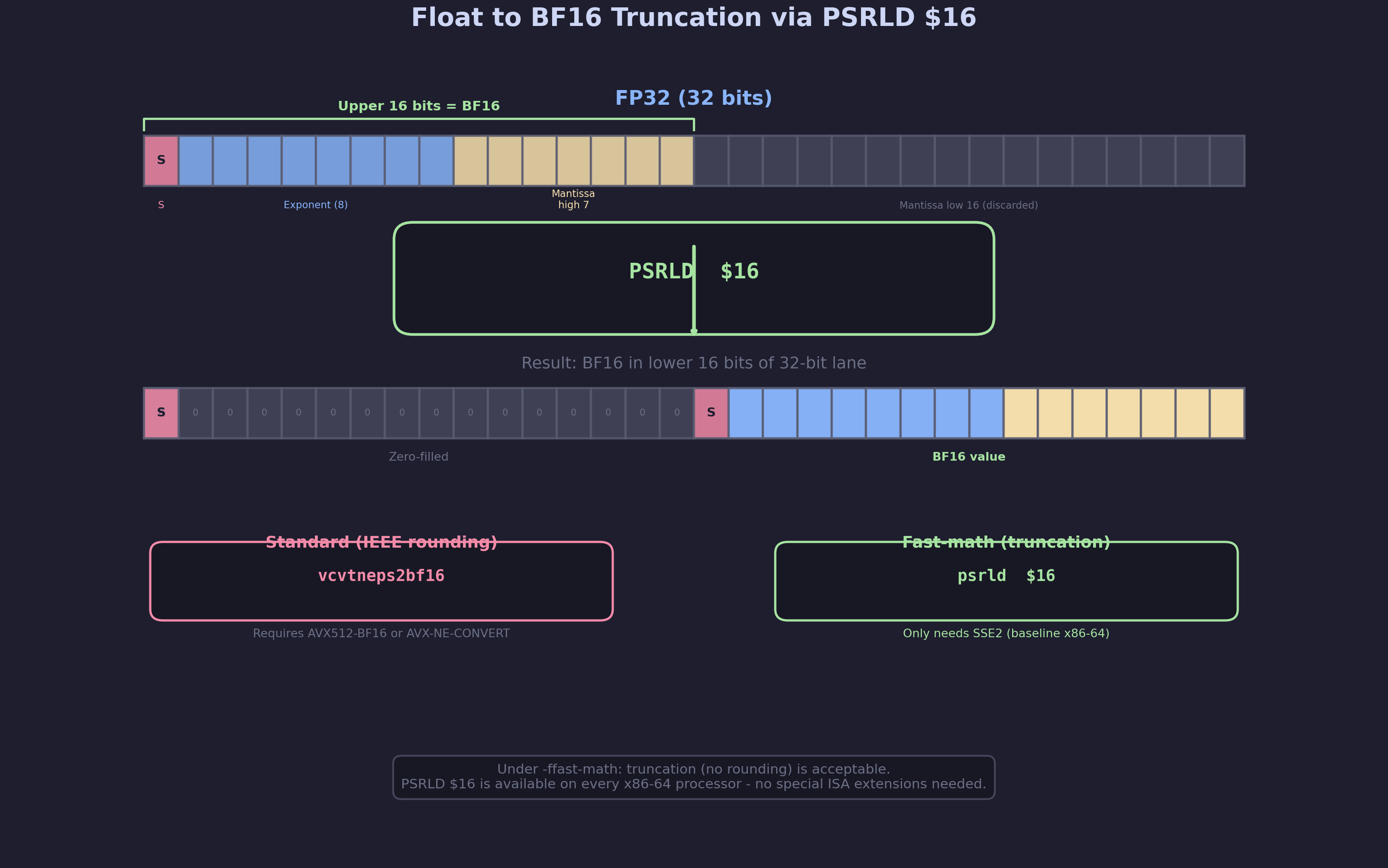
The caveat is rounding: a proper IEEE conversion should round the result to the nearest representable BF16 value. The dedicated vcvtneps2bf16 instruction handles rounding correctly (it uses “round to nearest even” with a tie-breaking rule). But the shift approach simply truncates – it always rounds toward zero, losing up to 1 ULP.
Under -ffast-math (which implies -fno-honor-nans and flag_unsafe_math_optimizations), this truncation behavior is acceptable. The programmer has explicitly opted into reduced precision guarantees for better performance.
The Implementation
The truncsfbf2 pattern in sse.md is extended with two new shift-based alternatives alongside the existing conversion instruction alternatives:
(define_insn "truncsfbf2"
[(set (match_operand:BF 0 "register_operand" "=x,x,v,Yv")
(float_truncate:BF
(match_operand:SF 1 "register_operand" "0,x,v,Yv")))]
"TARGET_SSE2 && flag_unsafe_math_optimizations && !HONOR_NANS (BFmode)"
"@
psrld\t{$16, %0|%0, 16}
%{vex%} vcvtneps2bf16\t{%1, %0|%0, %1}
vcvtneps2bf16\t{%1, %0|%0, %1}
vpsrld\t{$16, %1, %0|%0, %1, 16}"
[(set_attr "isa" "noavx,avxneconvert,avx512bf16vl,avx")
(set_attr "prefix" "orig,vex,evex,vex")
(set_attr "type" "sseishft1,ssecvt,ssecvt,sseishft1")])
The four alternatives in priority order:
psrld $16– SSE2 in-place shift (constraint"0"ties input to output, no AVX needed)vcvtneps2bf16– AVX-NE-CONVERT with VEX prefix (proper rounding, if available)vcvtneps2bf16– AVX512-BF16 with EVEX prefix (proper rounding, if available)vpsrld $16– AVX three-operand shift (different source and destination)
The register allocator picks the best alternative based on available ISA extensions. On hardware with AVX-NE-CONVERT or AVX512-BF16, the proper rounding instruction is preferred. On baseline SSE2 or AVX hardware without BF16 support, the shift alternatives provide a working (if less precise) fallback.
Why This Matters
Before this patch, converting float to BF16 on hardware without AVX512-BF16 required either a software emulation (multiple instructions to extract, round, and pack) or libgcc calls. With -ffast-math, this patch reduces it to a single instruction that’s available on every x86-64 processor ever made.
This is particularly valuable for inference workloads that target a wide range of hardware. A model quantized to BF16 can now run efficiently on older servers without AVX-512, as long as the application tolerates the truncation-vs-rounding precision difference (which is at most 1 ULP in the BF16 representation).
Test Cases
A compile test verifies psrld emission:
/* { dg-options "-msse2 -O2 -ffast-math" } */
/* { dg-final { scan-assembler-times "psrld" 1 } } */
__bf16 foo (float a) {
return a;
}
A comprehensive runtime test validates correctness across float values (0.0, 1.0, -1.0, 1000.0, -3.14, near FLT_MIN/FLT_MAX), verifying that the psrld result matches a reference implementation that manually shifts the float bits, and that the precision loss stays within the expected BF16 tolerance (2exponent-7).