
This patch has been committed to the master branch:
dd859e93a16 – Support Intel AMX-FP8
This patch adds GCC support for Intel AMX-FP8, a new extension to the Advanced Matrix Extensions (AMX) that performs tile-based matrix multiplication with 8-bit floating-point (FP8) operands and FP32 accumulation. AMX-FP8 doubles the compute density compared to AMX-BF16 by packing twice as many elements per tile register.
What is AMX?
Intel AMX (Advanced Matrix Extensions) provides hardware-accelerated matrix multiply operations using special “tile” registers (TMM0-TMM7). Each tile can hold up to 1KB of data (16 rows x 64 bytes), and tile multiply instructions compute the dot product of two tiles and accumulate the result into a third. AMX was introduced with Intel Sapphire Rapids for INT8 and BF16 matrix operations.
AMX-FP8 extends this with four new instructions that operate on 8-bit float formats, enabling higher throughput for AI workloads that can tolerate the reduced precision of FP8:
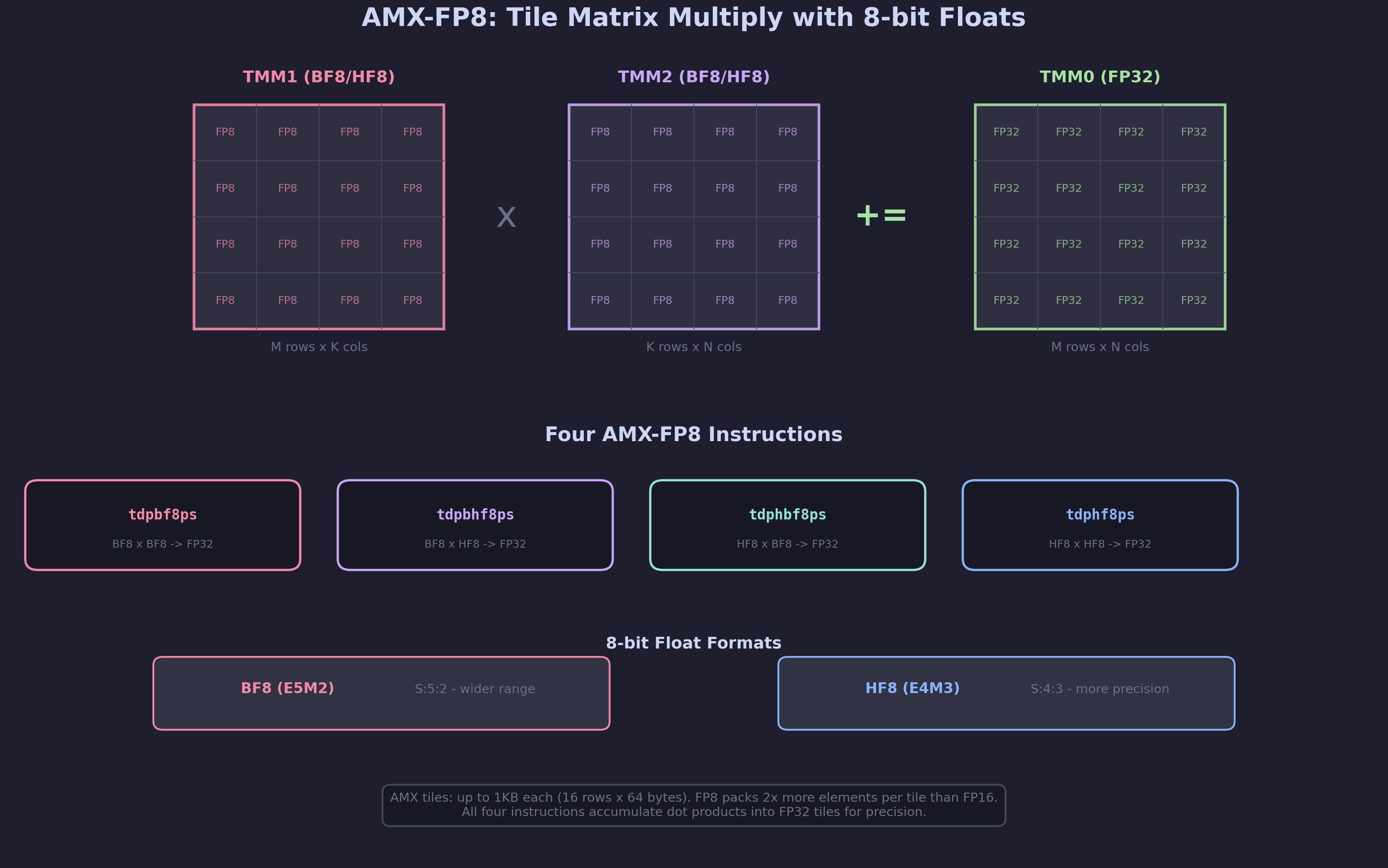
The Four Instructions
AMX-FP8 provides all four combinations of the two 8-bit float formats:
Instruction Source A Source B Accumulator ----------- -------- -------- ----------- tdpbf8ps BF8 BF8 FP32 tdpbhf8ps BF8 HF8 FP32 tdphbf8ps HF8 BF8 FP32 tdphf8ps HF8 HF8 FP32
The mixed-format variants (tdpbhf8ps, tdphbf8ps) are important for real AI workloads. Weights and activations often have different numerical distributions – weights might fit well in BF8’s wider dynamic range (E5M2), while activations benefit from HF8’s higher precision (E4M3). The four variants let the programmer choose the optimal format combination for each layer.
All four instructions accumulate into FP32 tiles. This is a key design choice: the intermediate dot-product accumulation happens at full 32-bit precision, preventing the catastrophic precision loss that would occur if 8-bit values were accumulated in 8-bit precision. The FP32 result can then be quantized back to FP8 for the next layer using the AVX10.2 conversion instructions.
Throughput Advantage
Since FP8 elements are half the size of FP16/BF16, each 1KB tile register can hold twice as many elements. For a tile matrix multiply, this means:
AMX-BF16: 16 rows x 32 BF16 elements = 512 elements/tile AMX-FP8: 16 rows x 64 FP8 elements = 1024 elements/tile Per tile multiply: AMX-BF16: 16 x 16 x 32 = 8,192 multiply-accumulate ops AMX-FP8: 16 x 16 x 64 = 16,384 multiply-accumulate ops (2x)
Implementation
The implementation follows the standard pattern for adding a new x86 ISA extension to GCC:
- Option handling –
-mamx-fp8flag added toi386.opt, with proper set/unset masks ini386-common.cc. Enabling-mamx-fp8automatically enables-mamx-tileas a dependency. - CPUID detection –
cpuinfo.hupdated to detect AMX-FP8 via CPUID leaf 7, sub-leaf 1, EDX bit 4 - Preprocessor macro –
__AMX_FP8__defined when the extension is enabled - Intrinsics header –
amxfp8intrin.hprovides the user-facing API
The intrinsics are implemented as inline assembly macros, matching the pattern used by other AMX instructions:
#define _tile_dpbf8ps_internal(dst,src1,src2) \
__asm__ volatile \
("{tdpbf8ps\t%%tmm"#src2", %%tmm"#src1", %%tmm"#dst \
"|tdpbf8ps\t%%tmm"#dst", %%tmm"#src1", %%tmm"#src2"}" ::)
#define _tile_dpbf8ps(dst,src1,src2) \
_tile_dpbf8ps_internal (dst,src1,src2)
Each macro accepts three tile register numbers (0-7) and emits the corresponding tdp*ps instruction in both AT&T and Intel syntax. The volatile qualifier prevents the compiler from reordering or eliminating the tile operations, which have side effects on the tile state that the compiler cannot model.
Usage Example
#include <immintrin.h> // Configure tiles _tile_loadconfig(&tile_config); // Load input tiles from memory _tile_loadd(1, A_ptr, stride_a); // TMM1 = BF8 matrix A _tile_loadd(2, B_ptr, stride_b); // TMM2 = BF8 matrix B // BF8 x BF8 matrix multiply, accumulate into FP32 tile _tile_dpbf8ps(0, 1, 2); // TMM0 += TMM1 * TMM2 // Mixed-format: BF8 x HF8 _tile_dpbhf8ps(0, 1, 2); // TMM0 += TMM1(BF8) * TMM2(HF8) // Store result _tile_stored(0, C_ptr, stride_c);
Test Coverage
The test suite includes compile-time checks verifying correct instruction emission for all four tile multiply variants, CPUID feature detection tests, and verification that -mamx-fp8 implies the required -mamx-tile dependency. A target-supports check (amx_fp8) is added to sourcebuild.texi for use in the DejaGnu test framework.