
These patches have been committed to the master branch:
8e16f26ca9f – i386: Support partial vectorized V2BF/V4BF plus/minus/mult/div/sqrt
62df24e5003 – i386: Support partial vectorized V2BF/V4BF smaxmin
f82fa0da4d9 – i386: Support vectorized BF16 add/sub/mul/div with AVX10.2
6d294fb8ac9 – i386: Support vectorized BF16 FMA with AVX10.2
29ef601973d – i386: Support vectorized BF16 smaxmin with AVX10.2
e19f65b0be1 – i386: Support vectorized BF16 sqrt with AVX10.2
f9ca3fd1fe3 – i386: Support partial vectorized FMA for V2BF/V4BF
3d031cc4465 – x86: Refine V4BF/V2BF FMA Testcase
This series of 8 commits enables GCC to auto-vectorize BF16 arithmetic operations using AVX10.2 native instructions. Previously, BF16 arithmetic required conversion to FP32 and back. With AVX10.2, the processor can operate on BF16 values directly, and these patches teach GCC to emit those instructions.
The FP32 Round-Trip Problem
Before AVX10.2, BF16 was a storage-only format on x86. To add two BF16 vectors, GCC had to:
- Convert both BF16 operands to FP32 (
vcvtbf162ps) - Perform the FP32 operation (
vaddps) - Convert the result back to BF16 (
vcvtne2ps2bf16)
This 3-instruction sequence also widens the data: eight BF16 elements in a 128-bit register become eight FP32 elements requiring a 256-bit register. For a tight vectorized loop, this round-trip conversion dominates the execution cost and doubles the register pressure.
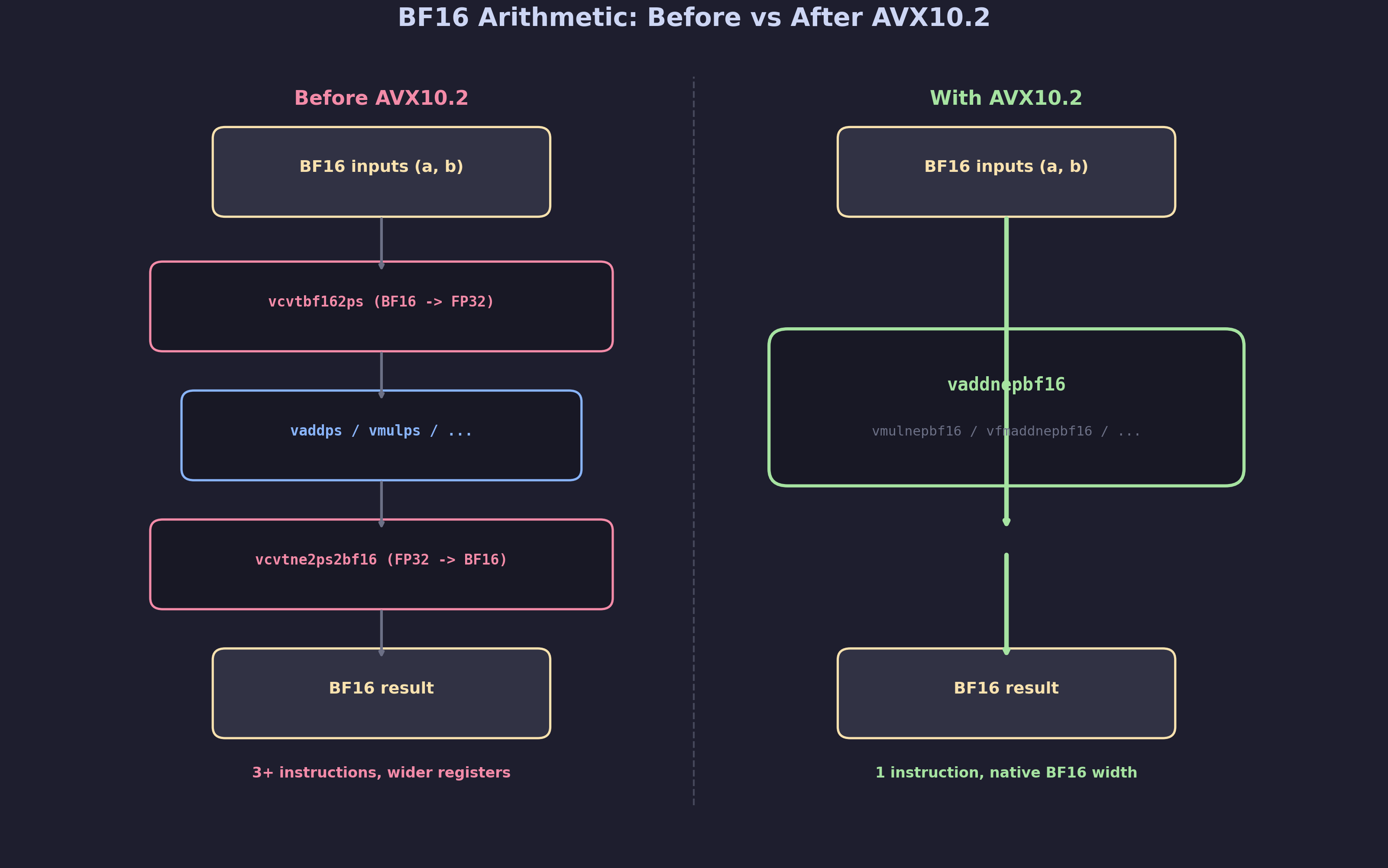
What AVX10.2 Brings
AVX10.2 introduces native BF16 arithmetic instructions that operate directly on packed BF16 vectors. The complete set enabled by this patch series:
Instruction Operation Commit ----------- --------- ------ vaddnepbf16 a + b f82fa0da4d9 vsubnepbf16 a - b f82fa0da4d9 vmulnepbf16 a * b f82fa0da4d9 vdivnepbf16 a / b f82fa0da4d9 vsqrtnepbf16 sqrt(a) e19f65b0be1 vfmadd132nepbf16 a*b + c (FMA) 6d294fb8ac9 vmaxpbf16 max(a, b) 29ef601973d vminpbf16 min(a, b) 29ef601973d
The “NE” in the instruction names stands for “Nearest Even” rounding, which is the IEEE 754 default rounding mode. Each instruction operates on the full packed BF16 vector without any format conversion.
Full-Width Vectors (V8BF/V16BF/V32BF)
The core changes are in sse.md. A new mode iterator VF_BHSD extends the existing VF (vector float) iterator to include BF16 modes:
;; VF_BHSD - BF16 + HF16 + SF + DF vector modes (define_mode_iterator VF_BHSD [(V32BF "TARGET_AVX10_2_512") (V16BF "TARGET_AVX10_2_256") (V8BF "TARGET_AVX10_2_256") ...])
By adding BF16 modes to the add/sub/mul/div patterns’ mode iterator, existing instruction templates automatically generate the correct BF16 variants. GCC’s machine description already handles the "ne" prefix through the sse attribute system.
FMA support is similarly enabled by adding V8BF/V16BF/V32BF to the FMAMODEM iterator, which covers fma, fms, fnma, and fnms patterns.
sqrt uses a new iterator VF2HB extending VF2H with BF modes, connecting to the vsqrtnepbf16 instruction.
smax/smin get a new dedicated expand pattern in sse.md:
(define_expand "<code><mode>3"
[(set (match_operand:VBF_AVX10_2 0 "register_operand")
(smaxmin:VBF_AVX10_2
(match_operand:VBF_AVX10_2 1 "nonimmediate_operand")
(match_operand:VBF_AVX10_2 2 "nonimmediate_operand")))]
"TARGET_AVX10_2_256"
"ix86_fixup_binary_operands_no_copy (<CODE>, <MODE>mode, operands);")
Partial Vectors (V2BF/V4BF)
For small loops that don’t fill a full 128-bit register, GCC uses partial vectorization with V2BF (32-bit, 2 elements) and V4BF (64-bit, 4 elements). These are handled in mmx.md with a widening strategy – the partial vector is widened to V8BF, the full-width instruction is used, and the result is extracted back:
(define_mode_iterator VBF_32_64
[(V4BF "TARGET_MMX_WITH_SSE") V2BF])
(define_expand "<insn><mode>3"
[(set (match_operand:VBF_32_64 0 "register_operand")
(plusminusmultdiv:VBF_32_64
(match_operand:VBF_32_64 1 "nonimmediate_operand")
(match_operand:VBF_32_64 2 "nonimmediate_operand")))]
"TARGET_AVX10_2_256"
{
rtx op0 = gen_reg_rtx (V8BFmode);
rtx op1 = lowpart_subreg (V8BFmode, force_reg (<MODE>mode, operands[1]),
<MODE>mode);
rtx op2 = lowpart_subreg (V8BFmode, force_reg (<MODE>mode, operands[2]),
<MODE>mode);
emit_insn (gen_<insn>v8bf3 (op0, op1, op2));
emit_move_insn (operands[0], lowpart_subreg (<MODE>mode, op0, V8BFmode));
DONE;
})
The partial vector patterns widen to V8BF, perform the operation using the full-width instruction, and extract the lower portion back. This same approach is used for all operations: arithmetic, FMA, sqrt, and smax/smin. The upper lanes contain garbage but are never read, so the widening is free.
Test Cases
Each commit includes tests verifying correct instruction selection. For example, the full-width arithmetic test:
/* { dg-do compile } */
/* { dg-options "-mavx10.2 -O2" } */
/* { dg-final { scan-assembler-times "vaddnepbf16" 2 } } */
/* { dg-final { scan-assembler-times "vsubnepbf16" 2 } } */
/* { dg-final { scan-assembler-times "vmulnepbf16" 2 } } */
/* { dg-final { scan-assembler-times "vdivnepbf16" 2 } } */
typedef __bf16 v8bf __attribute__((vector_size (16)));
typedef __bf16 v16bf __attribute__((vector_size (32)));
v8bf addv8bf (v8bf a, v8bf b) { return a + b; }
v16bf addv16bf (v16bf a, v16bf b) { return a + b; }
v8bf subv8bf (v8bf a, v8bf b) { return a - b; }
v16bf subv16bf (v16bf a, v16bf b) { return a - b; }
v8bf mulv8bf (v8bf a, v8bf b) { return a * b; }
v16bf mulv16bf (v16bf a, v16bf b) { return a * b; }
v8bf divv8bf (v8bf a, v8bf b) { return a / b; }
v16bf divv16bf (v16bf a, v16bf b) { return a / b; }
The scan-assembler count of 2 per instruction verifies that both V8BF (128-bit) and V16BF (256-bit) variants are being generated. The partial-vector FMA test additionally verifies vfmadd132nepbf16 emission for V2BF/V4BF loops.
Co-authored-by: Hongtao Liu ([email protected])