
These patches have been committed to the master branch:
b88adba751d – Optimize nested permutation to single VEC_PERM_EXPR
35106383c09 – Move scanning pass of forwprop-19.c to dse1
Bugzilla: PR tree-optimization/54346, PR testsuite/107220
This patch addresses PR 54346, a long-standing optimization opportunity in GCC’s middle-end tree optimization. When two consecutive vector permutations are nested – the result of the first feeding into both operands of the second – the two can be folded into a single VEC_PERM_EXPR by composing their selector indices. This eliminates an entire vector permutation instruction and the intermediate register it produces.
Background: What is VEC_PERM_EXPR?
In GCC’s GIMPLE intermediate representation, VEC_PERM_EXPR <op0, op1, selector> represents a vector permutation (shuffle) operation. It takes two input vectors op0 and op1, conceptually concatenates them into a doubled-length array, and uses the selector vector to pick elements from this combined space. For example, with 4-element integer vectors:
- Indices 0-3 select from the first operand
op0 - Indices 4-7 select from the second operand
op1
This operation is the backbone of all SIMD shuffle instructions across architectures – it maps to vperm2i128/vshufps/vpshufb on x86, tbl/trn/zip on AArch64, and equivalent instructions on other targets.
The Problem
Consider the following pattern in GIMPLE IR:
c = VEC_PERM_EXPR <a, b, VCST0>; d = VEC_PERM_EXPR <c, c, VCST1>;
The second permutation uses c as both its input operands. This means every element of d is selected from c, which is itself just a rearrangement of elements from a and b. The two-hop index chain can be collapsed into a single hop.
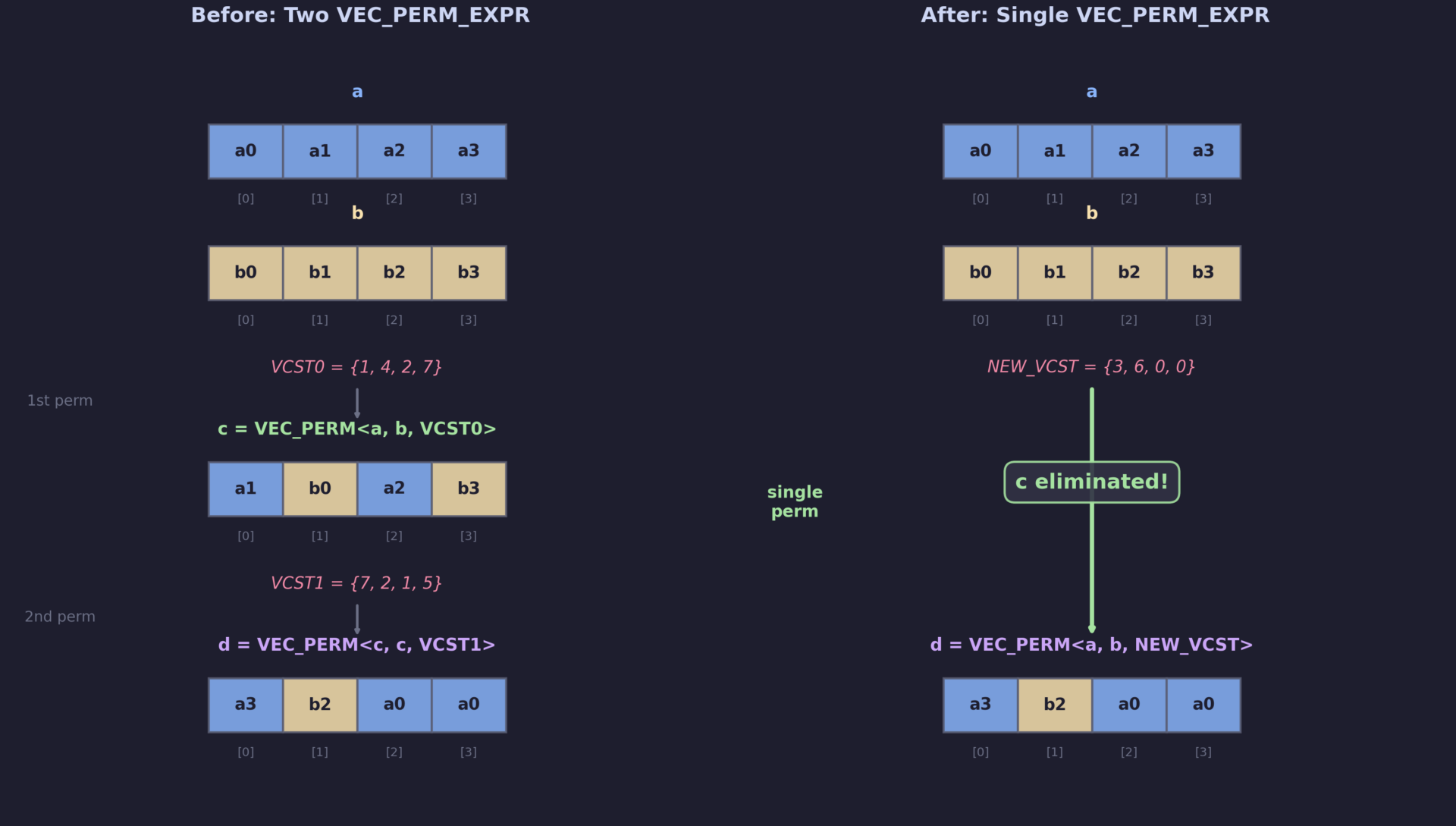
By computing a new composed selector, we can express the same result as a single operation directly on the original inputs:
d = VEC_PERM_EXPR <a, b, NEW_VCST>;
This eliminates one permutation instruction entirely, removes the intermediate vector c (which may free a register), and reduces both instruction count and register pressure.
How Index Composition Works
The key operation is composing two selector vectors. For each position i in the result:
- Look up
VCST1[i]to find which element ofcis selected - Follow that through
VCST0to find which element of the original(a, b)space thatcelement came from - That final index becomes
NEW_VCST[i]
In formula form: NEW_VCST[i] = VCST0[ VCST1[i] ]. Here is a concrete example:

In this example, VCST0 = {0, 5, 2, 7} and VCST1 = {2, 0, 3, 1}. The composed result is {2, 0, 7, 5}, which directly references elements from the original a (indices 0-3, blue) and b (indices 4-7, yellow) without the intermediate vector.
The Implementation
The optimization is implemented as a match.pd simplification rule. GCC’s match.pd is a domain-specific language for expressing tree-level pattern-matching transformations. Rules written in match.pd are automatically applied during forward propagation (forwprop) and other optimization passes that invoke the pattern matcher.
Here is how match.pd works at a high level: you specify a pattern (what to match in the IR) and a replacement (what to transform it into), with an optional with block for C++ computation in between. The framework handles traversal – when it encounters a tree node matching the pattern, it runs the replacement logic.
The core rule:
/* Merge
c = VEC_PERM_EXPR <a, b, VCST0>;
d = VEC_PERM_EXPR <c, c, VCST1>;
to
d = VEC_PERM_EXPR <a, b, NEW_VCST>; */
(simplify
(vec_perm (vec_perm@0 @1 @2 VECTOR_CST@3) @0 VECTOR_CST@4)
(with
{
if (!TYPE_VECTOR_SUBPARTS (type).is_constant ())
return NULL_TREE;
tree op0;
machine_mode result_mode = TYPE_MODE (type);
machine_mode op_mode = TYPE_MODE (TREE_TYPE (@1));
int nelts = TYPE_VECTOR_SUBPARTS (type).to_constant ();
vec_perm_builder builder0;
vec_perm_builder builder1;
vec_perm_builder builder2 (nelts, nelts, 1);
if (!tree_to_vec_perm_builder (&builder0, @3)
|| !tree_to_vec_perm_builder (&builder1, @4))
return NULL_TREE;
vec_perm_indices sel0 (builder0, 2, nelts);
vec_perm_indices sel1 (builder1, 1, nelts);
for (int i = 0; i < nelts; i++)
builder2.quick_push (sel0[sel1[i].to_constant ()]);
vec_perm_indices sel2 (builder2, 2, nelts);
if (!can_vec_perm_const_p (result_mode, op_mode, sel2, false))
return NULL_TREE;
op0 = vec_perm_indices_to_tree (TREE_TYPE (@4), sel2);
}
(vec_perm @1 @2 { op0; })))
Dissecting the Code
Let’s walk through each part of the implementation:
Pattern matching: (vec_perm (vec_perm@0 @1 @2 VECTOR_CST@3) @0 VECTOR_CST@4)
@0captures the innerVEC_PERM_EXPRresult. It appears as both the first and second operand of the outer permutation – this is the crucial constraint that both inputs are the same vectorc.@1and@2are the original input vectors (aandb).VECTOR_CST@3andVECTOR_CST@4capture the two selector constants. Both must be compile-time constant vectors for this optimization to apply.
Guard checks:
TYPE_VECTOR_SUBPARTS(type).is_constant()– Only constant-length vectors are handled. Variable-length vectors (as used in RISC-V V extension or SVE) would require a different approach since the number of elements isn’t known at compile time.tree_to_vec_perm_builder– Extracts the selector indices from the VECTOR_CST tree nodes intovec_perm_builderobjects that can be queried programmatically.
Index composition:
sel0is constructed with ninputs=2 andsel1with ninputs=1. This is the key asymmetry: the inner permutation selects from two distinct vectors (a, b) spanning indices 0 to 2*nelts-1, while the outer permutation selects from a single vector (c, c) so its indices wrap modulo nelts.- The composition loop
builder2.quick_push(sel0[sel1[i].to_constant()])performs the two-hop lookup for each element position.
Target validation:
can_vec_perm_const_p(result_mode, op_mode, sel2, false)asks the target backend whether it can actually implement the composed permutation in a single instruction (or acceptable instruction sequence). Not all permutations are cheap on all targets – for instance, crossing 128-bit lane boundaries on pre-AVX2 x86 is expensive. If the target can’t efficiently execute the combined permutation, the optimization is skipped, and the two-permutation sequence is kept.
Test Cases
The new test case gcc.dg/pr54346.c validates the optimization directly:
/* { dg-do compile } */
/* { dg-options "-O -fdump-tree-dse1" } */
typedef int veci __attribute__ ((vector_size (4 * sizeof (int))));
void fun (veci a, veci b, veci *i)
{
veci c = __builtin_shuffle (a, b, (veci) {1, 4, 2, 7});
*i = __builtin_shuffle (c, (veci) { 7, 2, 1, 5 });
}
/* { dg-final { scan-tree-dump "VEC_PERM_EXPR.*{ 3, 6, 0, 0 }" "dse1" } } */
/* { dg-final { scan-tree-dump-times "VEC_PERM_EXPR" 1 "dse1" } } */
The first shuffle selects elements {1, 4, 2, 7} from the concatenation of a (indices 0-3) and b (indices 4-7), producing intermediate vector c. The second shuffle then picks elements {7, 2, 1, 5} from (c, c).
After the optimization, GCC collapses these two shuffles into a single VEC_PERM_EXPR with the composed selector { 3, 6, 0, 0 }, directly referencing elements from the original a and b. The test verifies two things:
- The composed index vector
{ 3, 6, 0, 0 }appears in the tree dump - Only one
VEC_PERM_EXPRremains (the intermediate was eliminated)
Impact on Existing Tests
The new match.pd rule also changed where the existing forwprop-19.c test’s permutation folding occurs. This test had two nested shuffles that compose into an identity permutation – previously eliminated during forwprop1. With the new composed-permutation rule, the fold now happens earlier and the dead result is cleaned up by dse1 (Dead Store Elimination, pass 1) instead.
A follow-up commit (PR 107220) updated the test expectations accordingly:
-/* { dg-options "-O -fdump-tree-forwprop1" } */
+/* { dg-options "-O -fdump-tree-dse1" } */
...
-/* { dg-final { scan-tree-dump-not "VEC_PERM_EXPR" "forwprop1" } } */
+/* { dg-final { scan-tree-dump-not "VEC_PERM_EXPR" "dse1" } } */
This is a common consequence of adding new optimization rules in GCC’s pipeline – earlier folding shifts where downstream passes observe the results, requiring test scan targets to be updated.
Scope and Limitations
This optimization specifically handles the case where the outer permutation’s both operands are the same inner permutation result. Other nesting patterns – such as two different permutations feeding into the outer VEC_PERM_EXPR, or the inner result appearing as only one operand – are not covered by this rule and would require separate patterns.
The constant-length vector restriction (is_constant() guard) means this does not apply to scalable vectors used in architectures like AArch64 SVE or RISC-V V. Extending to variable-length vectors is possible but would need runtime index computation rather than compile-time folding.
Co-authored-by: Hongtao Liu ([email protected])