These patches have been committed to the master branch:
a71f90c5a7a – Add 3-instruction subroutine vector shift for V16QI
0022064649d – Fix Logical Shift Issue in expand_vec_perm_psrlw_psllw_por
Bugzilla: PR target/107563, PR target/115146
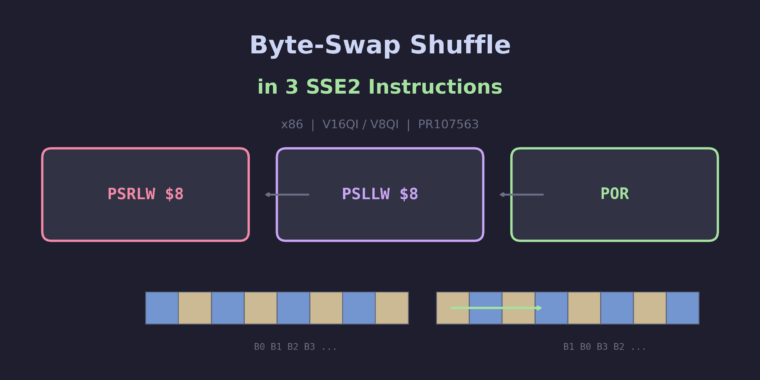
This pair of patches adds an efficient 3-instruction sequence for byte-swap permutations in V16QI and V8QI vectors on x86. Instead of falling through to a more expensive general-purpose shuffle, GCC now recognizes the adjacent byte-swap pattern and emits psrlw/psllw/por – a compact SSE2 sequence that works on all x86-64 targets without requiring any AVX extensions.
The Problem
Consider swapping adjacent bytes in a 16-byte vector:
using vec16 [[__gnu__::__vector_size__(16)]] = char;
void foo(vec16& v) noexcept {
v = __builtin_shufflevector(v, v,
1,0, 3,2, 5,4, 7,6, 9,8, 11,10, 13,12, 15,14);
}
Every pair of adjacent bytes is swapped: byte 0 swaps with byte 1, byte 2 with byte 3, and so on. This pattern is very common in practice – it appears in endianness conversion (byte-swapping 16-bit values in an array), certain cryptographic operations, and DSP code that processes interleaved real/imaginary samples.
Before this patch, GCC’s ix86_expand_vec_perm_const_1 had no specialized handler for this pattern. The function tries a series of increasingly expensive strategies to implement a given permutation, and this byte-swap pattern would fall through to a 4+ instruction general-purpose sequence. Since the pattern is both common and has a cheap implementation, adding a dedicated 3-instruction path is a clear win.
The Key Insight
If you reinterpret a V16QI (16 bytes) vector as V8HI (8 halfwords of 16 bits each), swapping adjacent bytes within each pair is equivalent to rotating each 16-bit halfword by 8 bits. This rotation can be decomposed into two shifts and an OR:
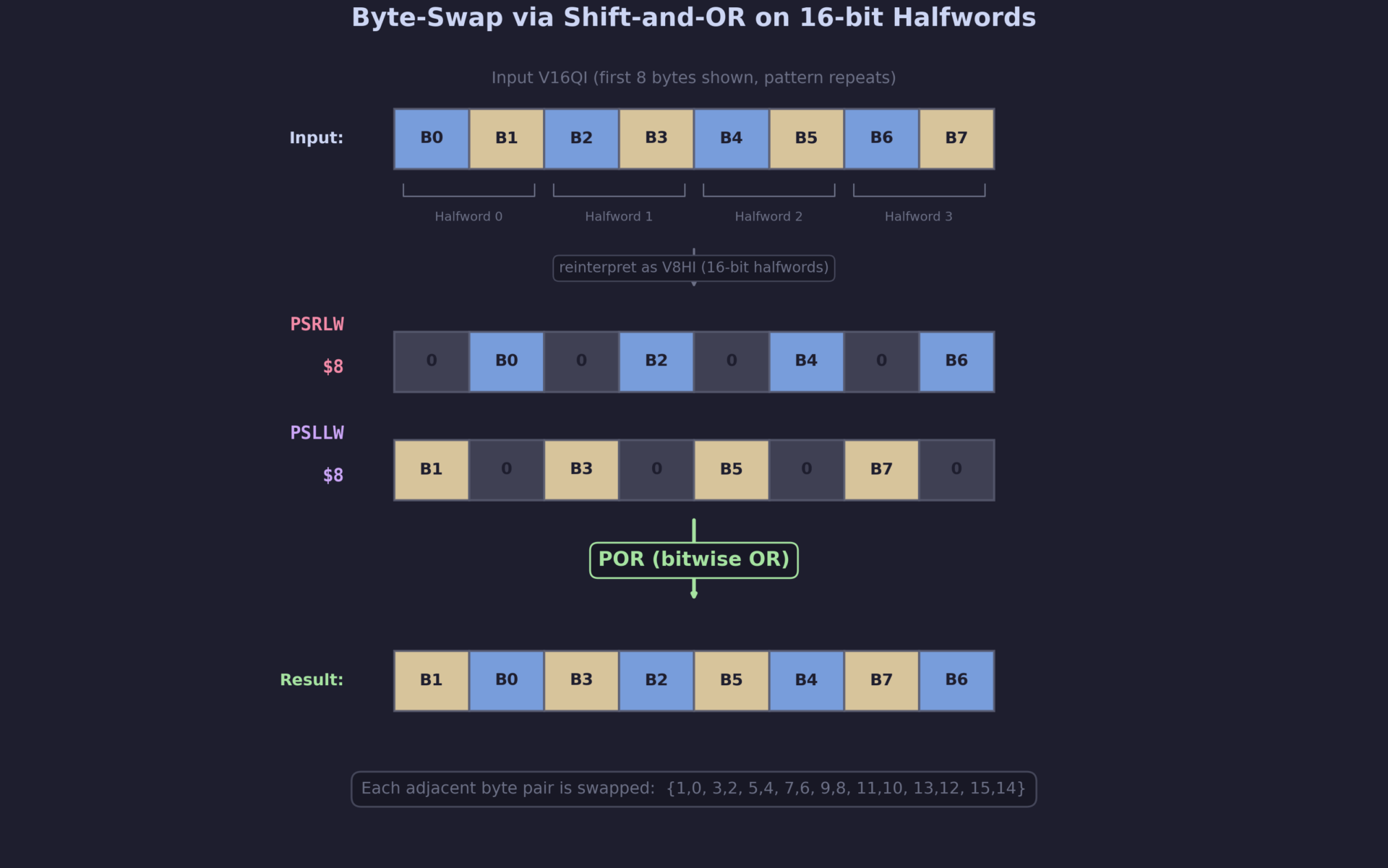
The three steps in detail:
PSRLW $8(logical right shift each halfword by 8 bits) – moves the high byte of each pair into the low byte position, filling the high byte with zeros. For halfword[B0, B1]this produces[0, B0].PSLLW $8(logical left shift each halfword by 8 bits) – moves the low byte into the high byte position, filling the low byte with zeros. For[B0, B1]this produces[B1, 0].POR(bitwise OR) – combines the two results:[0, B0] | [B1, 0] = [B1, B0]. The bytes are now swapped.
All three instructions are available in SSE2, which is baseline for all x86-64 processors. No AVX, SSSE3 (pshufb), or any other extension is required.
Where It Fits in GCC
GCC’s x86 backend handles constant vector permutations through ix86_expand_vec_perm_const_1 in i386-expand.cc. This function is a long chain of specialized subroutines, each trying to match a specific pattern class. The subroutines are ordered by cost – cheaper sequences (fewer instructions) are tried first:
- 1-instruction patterns (e.g.,
punpckl,pshufd) - 2-instruction patterns (e.g.,
pshufhw+pshuflw) - 3-instruction patterns – this is where our new subroutine is inserted
- 4+ instruction patterns (e.g.,
expand_vec_perm_even_odd_trunc)
The new subroutine expand_vec_perm_psrlw_psllw_por is inserted just before the 4-instruction section, ensuring it takes priority over more expensive alternatives.
The Implementation
static bool
expand_vec_perm_psrlw_psllw_por (struct expand_vec_perm_d *d)
{
unsigned i;
rtx (*gen_shr) (rtx, rtx, rtx);
rtx (*gen_shl) (rtx, rtx, rtx);
rtx (*gen_or) (rtx, rtx, rtx);
machine_mode mode = VOIDmode;
if (!TARGET_SSE2 || !d->one_operand_p)
return false;
switch (d->vmode)
{
case E_V8QImode:
if (!TARGET_MMX_WITH_SSE)
return false;
mode = V4HImode;
gen_shr = gen_lshrv4hi3;
gen_shl = gen_ashlv4hi3;
gen_or = gen_iorv4hi3;
break;
case E_V16QImode:
mode = V8HImode;
gen_shr = gen_lshrv8hi3;
gen_shl = gen_ashlv8hi3;
gen_or = gen_iorv8hi3;
break;
default: return false;
}
if (!rtx_equal_p (d->op0, d->op1))
return false;
for (i = 0; i < d->nelt; i += 2)
if (d->perm[i] != i + 1 || d->perm[i + 1] != i)
return false;
if (d->testing_p)
return true;
rtx tmp1 = gen_reg_rtx (mode);
rtx tmp2 = gen_reg_rtx (mode);
rtx op0 = force_reg (d->vmode, d->op0);
emit_move_insn (tmp1, lowpart_subreg (mode, op0, d->vmode));
emit_move_insn (tmp2, lowpart_subreg (mode, op0, d->vmode));
emit_insn (gen_shr (tmp1, tmp1, GEN_INT (8)));
emit_insn (gen_shl (tmp2, tmp2, GEN_INT (8)));
emit_insn (gen_or (tmp1, tmp1, tmp2));
emit_move_insn (d->target, lowpart_subreg (d->vmode, tmp1, mode));
return true;
}
Let’s walk through the key parts:
Guard checks:
!TARGET_SSE2– requires at minimum SSE2!d->one_operand_p– the shuffle must use a single operand (both inputs are the same vector)- The
switchselects the appropriate halfword mode: V16QI (128-bit SSE) uses V8HI, V8QI (64-bit MMX-with-SSE) uses V4HI !rtx_equal_p(d->op0, d->op1)– double-checks both operands are indeed the same register
Pattern validation:
for (i = 0; i < d->nelt; i += 2)
if (d->perm[i] != i + 1 || d->perm[i + 1] != i)
return false;
This loop checks every consecutive pair: at even index i, the permutation must select i+1 (the next byte), and at odd index i+1, it must select i (the previous byte). This precisely matches the adjacent byte-swap pattern: {1,0, 3,2, 5,4, ...}.
Code emission: The input byte vector is reinterpreted as halfwords via lowpart_subreg (a zero-cost reinterpretation – no instruction emitted). Two copies are made: one shifted right by 8, one shifted left by 8, then ORed together. The result is reinterpreted back to the byte vector mode.
The Bug Fix (PR115146)
The initial implementation had a subtle but serious bug: it used arithmetic right shift (gen_ashrv4hi3) instead of logical right shift for the V8QI case. The difference:
- Arithmetic shift right: extends the sign bit. For a halfword
0x8C00, shifting right by 8 gives0xFF8C(the 1 in bit 15 fills the upper byte). - Logical shift right: fills with zeros. For
0x8C00, shifting right by 8 gives0x008C(correct).
This meant any byte with value ≥ 128 (0x80) would be corrupted by sign extension after the swap. The bug only manifested for values in the 128-255 range, making it easy to miss in basic testing.
The follow-up commit fixed this by replacing gen_ashrv4hi3 with gen_lshrv4hi3, and also corrected the V16QI generators from the “v-prefixed” internal forms (gen_vlshrv8hi3/gen_vashlv8hi3) to the standard forms (gen_lshrv8hi3/gen_ashlv8hi3). A runtime test case using values 140-147 (all ≥ 128) was added to catch this class of bug in the future.
The existing compile-time tests were also updated with -mno-sse3 to prevent SSSE3’s more powerful pshufb instruction from being selected on hosts that support it, ensuring the psrlw/psllw/por path is actually exercised by the test.
Test Cases
The compile-time test for V16QI (128-bit) verifies exactly the three expected instructions:
/* PR target/107563.C */
/* { dg-options "-std=c++2b -O3 -msse2 -mno-sse3" } */
/* { dg-final { scan-assembler-times "psllw" 1 } } */
/* { dg-final { scan-assembler-times "psrlw" 1 } } */
/* { dg-final { scan-assembler-times "por" 1 } } */
using temp_vec_type [[__gnu__::__vector_size__(16)]] = char;
void foo(temp_vec_type& v) noexcept {
v = __builtin_shufflevector(v, v,
1, 0, 3, 2, 5, 4, 7, 6, 9, 8, 11, 10, 13, 12, 15, 14);
}
And the runtime correctness test for the bugfix, using byte values above 128:
/* { dg-do run { target sse2_runtime } } */
/* { dg-options "-O2 -msse2" } */
typedef unsigned char v8qi __attribute__((vector_size (8)));
v8qi res, a;
void __attribute__((noipa))
foo (void) {
res = __builtin_shufflevector(a, a, 1, 0, 3, 2, 5, 4, 7, 6);
}
int main() {
/* Values 140-147 are all >= 128, triggering arithmetic shift bug */
a = (v8qi) { 140, 141, 142, 143, 144, 145, 146, 147 };
foo ();
comp (res, ((v8qi) { 141, 140, 143, 142, 145, 144, 147, 146 }), 8);
return 0;
}
Why Not PSHUFB?
On SSSE3+ processors, pshufb can implement any arbitrary byte permutation in a single instruction and would be the obvious choice. However, SSSE3 is not universally available – older Pentium 4 and early AMD64 processors only support SSE2. By using the shift-and-OR approach, this optimization benefits all x86-64 targets.
When SSSE3 is available, GCC’s earlier subroutines in the permutation expansion chain will match pshufb first (it’s a 1-instruction solution), so this 3-instruction path is only reached when pshufb is not available. The -mno-sse3 flag in the tests explicitly disables this to ensure our path is tested.
Co-authored-by: H.J. Lu ([email protected])