This patch has been committed to the master branch:
6d0b7b69d14 – Emit cvtne2ps2bf16 for odd increasing perm in __builtin_shufflevector
This patch teaches GCC’s x86 backend to recognize a specific BF16 vector shuffle pattern – selecting every odd element from two concatenated vectors – and lower it to the vcvtne2ps2bf16 instruction instead of a general-purpose byte permutation. The trick exploits the fact that BF16 is defined as the upper 16 bits of an IEEE 754 FP32 value, so extracting odd-indexed BF16 elements from packed 32-bit lanes is mathematically equivalent to the float-to-bfloat16 conversion that vcvtne2ps2bf16 already performs.
The Problem
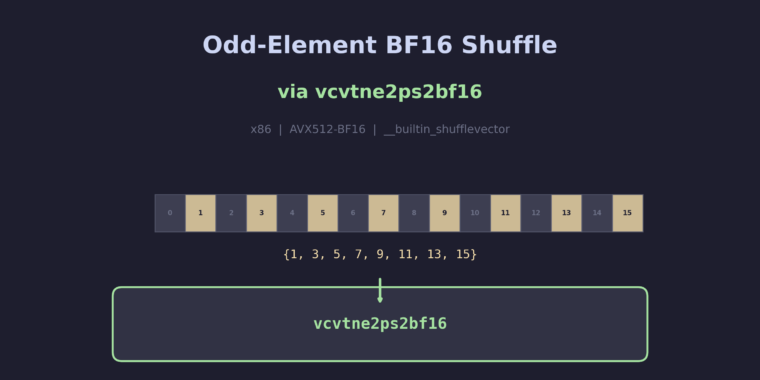
Consider selecting every odd-indexed element from two BF16 vectors:
typedef __bf16 v8bf __attribute__((vector_size(16)));
v8bf foo(v8bf a, v8bf b) {
return __builtin_shufflevector(a, b, 1, 3, 5, 7, 9, 11, 13, 15);
}
The selector {1, 3, 5, 7, 9, 11, 13, 15} picks elements at positions 1, 3, 5, 7 from a and 9, 11, 13, 15 from b – every odd index from the concatenated space. Without this patch, GCC would lower this to a general vpermi2b byte permutation, which is significantly more expensive.
On most x86 microarchitectures, vpermi2b has a latency of 5-8 cycles and requires building a 16/32/64-byte index vector first. In contrast, vcvtne2ps2bf16 runs in 3-4 cycles with no auxiliary data needed.
The Key Insight: BF16 and FP32 Bit Layout
The optimization hinges on a fundamental property of the BF16 format. BF16 (Brain Floating Point 16) was designed as a truncated form of IEEE 754 FP32 – it keeps the sign bit, all 8 exponent bits, and the top 7 mantissa bits, discarding the lower 16 bits of precision:
FP32: [S | EEEEEEEE | MMMMMMM MMMMMMMM MMMMMMMM]
^ 8 bits 23 bits mantissa
sign
BF16: [S | EEEEEEEE | MMMMMMM]
^ 8 bits 7 bits
sign
So: FP32 = BF16_value << 16 | lower_16_bits
This means that when two BF16 values sit adjacent in a 32-bit lane (as happens when you have a BF16 vector), the even-indexed BF16 occupies the low 16 bits and the odd-indexed BF16 occupies the high 16 bits. If you reinterpret that 32-bit lane as a float, the high 16 bits are exactly the BF16 value at the odd position.
The vcvtne2ps2bf16 instruction converts two FP32 vectors to BF16 by extracting the upper 16 bits of each 32-bit element and packing them. When the "floats" are actually BF16 pairs, this extraction produces exactly the odd-element shuffle we want.

Where It Fits in GCC
The x86 backend handles vector shuffles through ix86_expand_vec_perm_const in i386-expand.cc. When a __builtin_shufflevector or VEC_PERM_EXPR reaches the backend, GCC tries a cascade of pattern matchers to find the cheapest instruction sequence. Without this patch, BF16 odd-element shuffles fall through to the generic vpermt2 path, which uses the expensive byte-granularity permutation instruction.
This patch adds an earlier exit: before reaching the generic path, the backend now checks whether the permutation indices form the odd-increasing sequence {1, 3, 5, 7, ...}. If they do and the target supports AVX512-BF16, the shuffle is rewritten to use vcvtne2ps2bf16 instead.
The Implementation
The patch has three components:
1. Mode handling in ix86_vectorize_vec_perm_const - BF16 vectors are now converted to HI mode via subreg alongside the existing HF16 path:
- /* For HF mode vector, convert it to HI using subreg. */ - if (GET_MODE_INNER (vmode) == HFmode) + /* For HF and BF mode vector, convert it to HI using subreg. */ + if (GET_MODE_INNER (vmode) == HFmode || GET_MODE_INNER (vmode) == BFmode)
GCC's RTL doesn't natively support arithmetic or permutation operations on BF16 modes, so the standard approach is to lowpart_subreg them into 16-bit integer (HI) mode. This change extends the existing HF (half-float, FP16) handling to also cover BF (bfloat16), ensuring that subsequent pattern matchers see the permutation in HI mode and can match it.
2. New predicate vcvtne2ps2bf_parallel in predicates.md - validates that the permutation selector is the odd-increasing sequence {1, 3, 5, ...}:
;; Check that each element is odd and incrementally increasing from 1
(define_predicate "vcvtne2ps2bf_parallel"
(and (match_code "const_vector")
(match_code "const_int" "a"))
{
for (int i = 0; i < XVECLEN (op, 0); ++i)
if (INTVAL (XVECEXP (op, 0, i)) != (2 * i + 1))
return false;
return true;
})
The predicate walks the PARALLEL vector and verifies each index follows the formula 2*i + 1. For a vector of N elements, this checks for the sequence {1, 3, 5, ..., 2N-1}. The predicate is defined in GCC's machine description language and gets compiled into a C function that the instruction selector calls during pattern matching.
3. New define_insn_and_split in sse.md - matches the vpermt2 unspec with the odd-increasing predicate and splits it into vcvtne2ps2bf16:
(define_insn_and_split "vpermt2_sepcial_bf16_shuffle_<mode>"
[(set (match_operand:VI2_AVX512F 0 "register_operand")
(unspec:VI2_AVX512F
[(match_operand:VI2_AVX512F 1 "vcvtne2ps2bf_parallel")
(match_operand:VI2_AVX512F 2 "register_operand")
(match_operand:VI2_AVX512F 3 "nonimmediate_operand")]
UNSPEC_VPERMT2))]
"TARGET_AVX512VL && TARGET_AVX512BF16 && ix86_pre_reload_split ()"
"#"
"&& 1"
[(const_int 0)]
{
rtx op0 = gen_reg_rtx (<HI_CVT_BF>mode);
operands[2] = lowpart_subreg (<ssePSmode>mode,
force_reg (<MODE>mode, operands[2]),
<MODE>mode);
operands[3] = lowpart_subreg (<ssePSmode>mode,
force_reg (<MODE>mode, operands[3]),
<MODE>mode);
emit_insn (gen_avx512f_cvtne2ps2bf16_<hi_cvt_bf>(op0,
operands[3],
operands[2]));
emit_move_insn (operands[0], lowpart_subreg (<MODE>mode, op0,
<HI_CVT_BF>mode));
DONE;
}
[(set_attr "mode" "<sseinsnmode>")])
Let's walk through the split logic step by step:
- Pattern matching: The
define_insn_and_splitfires when the RTL contains aUNSPEC_VPERMT2(the generic two-source permutation) whose selector operand (operand 1) satisfiesvcvtne2ps2bf_parallel- i.e., the indices are{1, 3, 5, ...}. - Mode conversion:
operands[2]andoperands[3](the two source vectors in HI mode) are reinterpreted as PS (single-precision float) mode vialowpart_subreg. This is a zero-cost bitcast - no instruction is emitted, just a register renaming. - Instruction emission:
gen_avx512f_cvtne2ps2bf16is called with the "float" operands. This emits the actualvcvtne2ps2bf16instruction, which extracts the upper 16 bits from each 32-bit lane and packs them. - Result conversion: The output (in BF16 mode) is moved back to the original HI mode via another
lowpart_subreg.
Note that operands[3] comes before operands[2] in the gen_avx512f_cvtne2ps2bf16 call. This is because vcvtne2ps2bf16 processes its second operand into the lower half and its first operand into the upper half of the result, so the argument order must be swapped to preserve the correct element ordering from the original two-source permutation.
Why Not Just Use PSHUFB?
PSHUFB (byte shuffle) could also implement this pattern by selecting the appropriate bytes, but it has two significant drawbacks for this use case:
- Single-source only:
PSHUFBoperates on a single source vector. To shuffle elements from two vectors, you'd need twoPSHUFBinstructions plus a blend - three instructions instead of one. - 128-bit lane restriction: On AVX2/AVX-512,
VPSHUFBoperates within each 128-bit lane independently. Selecting odd elements across the full 256-bit or 512-bit vector would require additional cross-lane operations.
vcvtne2ps2bf16 avoids both issues: it takes two source vectors and operates across the full vector width in a single instruction.
Compiler Output
Before this patch, the 128-bit case compiled to:
foo:
vmovdqa xmm2, XMMWORD PTR .LC0[rip] # load 16-byte index vector
vpermi2b xmm2, xmm0, xmm1 # generic byte permutation
vmovdqa xmm0, xmm2
ret
After:
foo:
vcvtne2ps2bf16 xmm0, xmm1, xmm0 # single instruction!
ret
The improvement is clear: we go from a memory load plus a multi-cycle byte permutation to a single register-to-register instruction with no auxiliary data.
Test Case
/* { dg-do compile } */
/* { dg-options "-O2 -mavx512bf16 -mavx512vl" } */
/* { dg-final { scan-assembler-not "vpermi2b" } } */
/* { dg-final { scan-assembler-times "vcvtne2ps2bf16" 3 } } */
typedef __bf16 v8bf __attribute__((vector_size(16)));
typedef __bf16 v16bf __attribute__((vector_size(32)));
typedef __bf16 v32bf __attribute__((vector_size(64)));
v8bf foo0(v8bf a, v8bf b) {
return __builtin_shufflevector(a, b, 1, 3, 5, 7, 9, 11, 13, 15);
}
v16bf foo1(v16bf a, v16bf b) {
return __builtin_shufflevector(a, b, 1, 3, 5, 7, 9, 11, 13, 15,
17, 19, 21, 23, 25, 27, 29, 31);
}
v32bf foo2(v32bf a, v32bf b) {
return __builtin_shufflevector(a, b, 1, 3, 5, 7, 9, 11, 13, 15,
17, 19, 21, 23, 25, 27, 29, 31,
33, 35, 37, 39, 41, 43, 45, 47,
49, 51, 53, 55, 57, 59, 61, 63);
}
The test covers all three BF16 vector widths (128-bit, 256-bit, 512-bit) and verifies that vcvtne2ps2bf16 is emitted 3 times while the generic vpermi2b is not used. The negative scan-assembler check is important: it confirms GCC doesn't fall back to the generic path for any of the three vector widths.
Scope and Limitations
This optimization only fires when all of the following hold:
- The shuffle source type is V8HI, V16HI, or V32HI (16-bit integer mode, which BF16 is lowered into)
- The permutation indices are exactly
{1, 3, 5, ..., 2N-1}- the odd-increasing pattern - The target has both
TARGET_AVX512VLandTARGET_AVX512BF16 - We're in the pre-reload split phase (
ix86_pre_reload_split)
The even-element case ({0, 2, 4, 6, ...}) is not handled by this patch. Extracting even elements would require selecting the lower 16 bits of each 32-bit lane, and there's no single x86 instruction that does this. The even case would still need a byte permutation or a shift-and-pack sequence.