This patch has been committed to the master branch:
2a046117a83 – AVX10.2: Support convert instructions
This patch adds GCC intrinsic support for the AVX10.2 conversion instructions – a new set of instructions for converting between FP16, BF16, FP8 (HF8/BF8), and FP32 formats with various rounding and saturation options. These instructions are the hardware backbone of mixed-precision AI inference and training pipelines on future Intel processors.
Why New Conversion Instructions?
Modern AI workloads use multiple floating-point precisions in a single pipeline. Weights might be stored in 8-bit float for memory efficiency, activations computed in FP16 or BF16 for speed, and critical accumulations done in FP32 for accuracy. Each precision boundary requires a format conversion, and on current hardware these conversions are often multi-instruction sequences. AVX10.2 makes them single instructions:
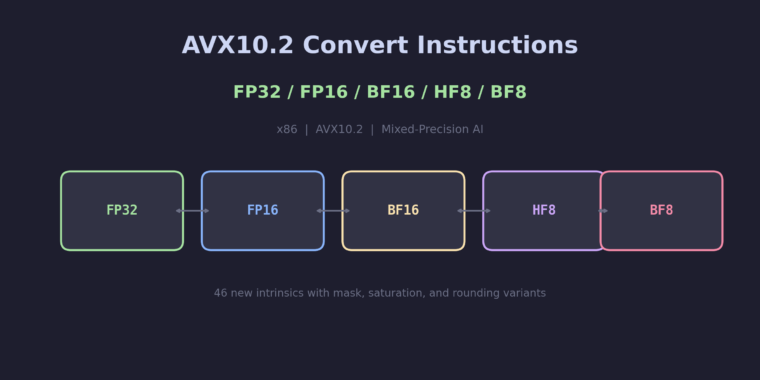
The New Floating-Point Formats
AVX10.2 introduces two 8-bit float formats alongside the existing FP32, FP16, and BF16:
Format Bits Layout Range Use Case ------ ---- ----------- ---------------- -------- FP32 32 S:8:23 ~1.2e-38 to 3.4e38 Accumulation FP16 16 S:5:10 ~6.1e-5 to 65504 Compute BF16 16 S:8:7 ~1.2e-38 to 3.4e38 Compute (wider range) HF8 8 S:4:3 ~0.0625 to 240 Weight storage BF8 8 S:5:2 ~6.1e-8 to 57344 Weight storage (wider range)
HF8 (IEEE FP8 E4M3) has more mantissa precision, making it better for storing values that cluster around a narrow range. BF8 (IEEE FP8 E5M2) has more exponent range, making it better for values spanning many orders of magnitude. The choice depends on the layer’s weight distribution.
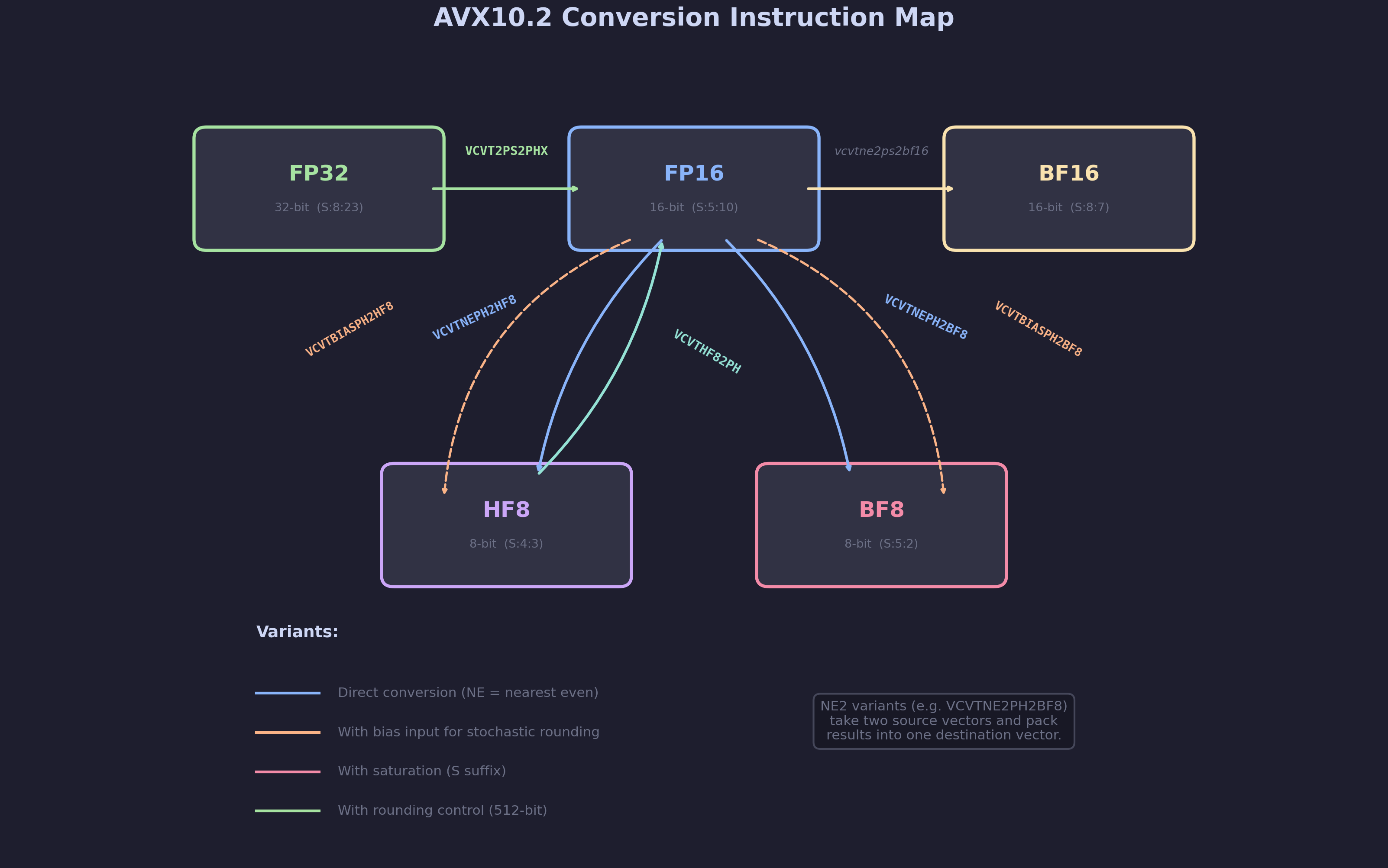
Instruction Categories
The conversion instructions fall into four categories:
1. Direct conversion (NE = Nearest Even)
// FP16 -> HF8 (nearest even rounding) __m128i _mm_cvtneph_hf8(__m128h A); __m128i _mm256_cvtneph_hf8(__m256h A); // FP16 -> BF8 __m128i _mm_cvtneph_bf8(__m128h A); // HF8 -> FP16 (exact, no rounding needed) __m128h _mm_cvthf8_ph(__m128i A); __m256h _mm256_cvthf8_ph(__m128i A);
2. Two-source packing (NE2 variants) – these take two source vectors and interleave the converted results into one destination:
// Two FP32 vectors -> one FP16 vector (2x packing) __m128h _mm256_cvt2ps_phx(__m256 A, __m256 B); // Two FP16 vectors -> one HF8 vector (2x packing) __m128i _mm_cvtne2ph_hf8(__m128h A, __m128h B); __m256i _mm256_cvtne2ph_hf8(__m256h A, __m256h B);
3. Biased conversion – adds a bias value before converting, enabling stochastic rounding for training:
// FP16 -> HF8 with bias (for stochastic rounding) __m128i _mm_cvtbiasph_hf8(__m128i bias, __m128h A); __m128i _mm_cvtbiasph_hf8s(__m128i bias, __m128h A); // with saturation
4. Saturation variants (S suffix) – clamp out-of-range values to the maximum representable value instead of producing infinity or NaN:
// Without saturation: overflow -> infinity __m128i _mm_cvtneph_bf8(__m128h A); // With saturation: overflow -> max representable __m128i _mm_cvtneph_bf8s(__m128h A);
Implementation Details
The implementation spans several files:
avx10_2convertintrin.h(978 lines) – 128-bit and 256-bit intrinsics with masking variantsavx10_2-512convertintrin.h(548 lines) – 512-bit variantsi386-builtin.def– 46 new builtin definitionsi386-builtin-types.def– new function type signatures for the mixed-width conversionssse.md– machine description patterns with rounding control support
A key implementation challenge is handling the mixed-width nature of these conversions. When converting FP16 (16-bit) to HF8 (8-bit), the destination is half the width of the source. The intrinsic headers handle this by using wider integer types for the 8-bit results and zeroing the upper portion:
// 256-bit FP16 (16 elements) -> 128-bit HF8 (16 elements, half the bytes)
extern __inline __m128i
__attribute__((__gnu_inline__, __always_inline__, __artificial__))
_mm256_cvtneph_hf8 (__m256h __A)
{
return (__m128i) __builtin_ia32_vcvtneph2hf8_256 ((__v16hf) __A);
}
Each instruction also supports masked variants (merge-masking and zero-masking) across all three vector widths (128-bit, 256-bit, 512-bit where applicable). The 512-bit forms additionally support embedded rounding control, allowing the programmer to specify the rounding mode per-instruction rather than modifying the global MXCSR register.
Test Coverage
The patch includes over 30 new test files covering each instruction variant. Compile-time tests verify correct instruction selection via scan-assembler directives, and runtime tests validate conversion results against reference implementations. The tests cover edge cases including denormals, infinities, NaN propagation, and saturation behavior.